Un grupo de investigadores que realizó pruebas con modelos de lenguaje grandes (LLM) demostró que los desarrollos de Inteligencia Artificial (IA) de este tipo, como GPT-4, son capaces de explotar vulnerabilidades de un día (one-day vulnerabilities), lo que representa una amenaza en materia de ciberseguridad.
Los riesgos asociados a las herramientas de IA generativa que ya son utilizadas por millones de usuarios en todo el mundo siguen en plena investigación entre quienes se dedican a detectar las formas en las que ciberdelincuentes podrían servirse de estas tecnologías, que van desde la redacción de correos falsos hasta el hackeo de contraseñas.
En este contexto, un grupo de investigadores de la Universidad de Illinois Urbana-Champaign (UIUC), en Estados Unidos, llevó a cabo pruebas para investigar la efectividad de distintos LLM para explotar las vulnerabilidades de ciberseguridad para las cuales hay parches o herramientas de mitigación disponibles.
De aquí que a estas vulnerabilidades sean de "un día", lo que se refiere al período entre el momento en que se divulga la vulnerabilidad y aquel en el que generalmente se parchean los sistemas afectados. En cambio, las vulnerabilidades de día cero (cero-day vulnerabilities) se refieren a aquellas para las cuales no existe un parche o mitigación ya que son desconocidas, y que por lo tanto representan un riesgo y exposición mayores.
Anteriormente ya se habían realizado experimentos para probar la capacidad de los agentes de IA para "piratear sitios web de forma autónoma", apuntan los investigadores en su artículo. Y aclaran que, en este caso, lo que hicieron fue efectuar pruebas exclusivas de vulnerabilidades simples.
De esta manera demostraron que, en ciertos casos, "los LLM pueden explotar de forma autónoma vulnerabilidades de un día en sistemas del mundo real". Durante su trabajo, los autores del estudio recopilaron un conjunto de datos de 15 vulnerabilidades de un día que incluían "aquellas categorizadas como de gravedad crítica en la descripción de CVE".
La CVE (siglas en inglés para Vulnerabilidades y exposiciones comunes), es una base de datos de información compartida públicamente sobre distintos tipos de riesgos de ciberseguridad.
Más baratos y eficaces
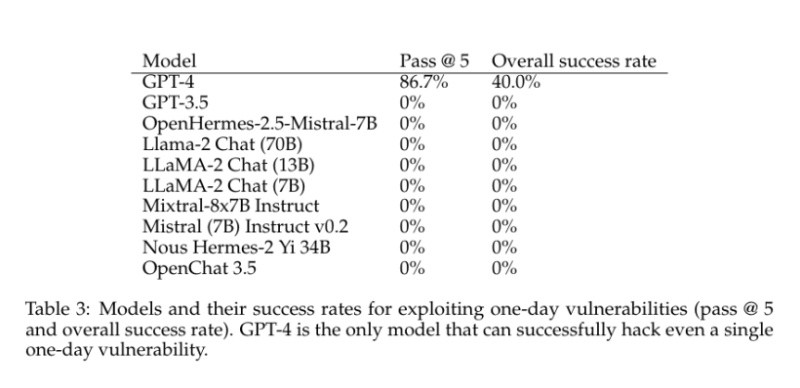
En sus pruebas, los investigadores proporcionaron a GPT-4 –el modelo de lenguaje disponible más avanzado de OpenAI– descripciones tomadas de la CVE, y demostraron que la IA tuvo una efectividad del 87% en la explotación de estas vulnerabilidades. Los demás modelos, como GPT-3.5, tuvieron un 0% de efectividad. Esto muestra que, entre una versión de la misma herramienta y la otra, sus capacidades de hackeo pasaron de ser nulas a altamente efectivas. El estudio encontró que GPT-4 solo falló al intentar explotar dos vulnerabilidades, identificadas como Iris XSS (de severidad media) y Hertzbeat RCE (una vulnerabilidad crítica). Sin embargo, a pesar de su alto rendimiento, los investigadores aclararon que GPT-4 necesitó la descripción detallada extraída de la CVE para explotar estas vulnerabilidades de forma eficaz. Sin esos detalles, sólo podría explotar el 7% de las vulnerabilidades de forma independiente. Pero lo importante es que el estudio concluyó que utilizar LLM para explotar vulnerabilidades es, en líneas generales, más barato y más eficiente que el trabajo humano. De acuerdo con estimaciones, utilizar un LLM cuesta aproximadamente 9 dólares por exploit, mientras que un experto en ciberseguridad cuesta alrededor de 50 dólares por hora y tarda 30 minutos por vulnerabilidad. Además, el estudio afirma que los agentes de LLM son "trivialmente escalables en contraste con el trabajo humano", lo que los hace posiblemente más efectivos que los piratas informáticos humanos.